【Java】try~catch文のcatch処理で使われるprintStackTrace()とは一体何か?

今回は、Javaのtry~catch文に言及した内容の記事を書いてみることにしました。
try~catch文のcatch処理の中に
e.printStackTrace();という処理が使われることがあるのですが、この処理は一体何のために書いているのか、過去のソースで普通に書いていたのに説明する記事を書いていませんでした。
そこで、catch文の中に
e.printStackTrace();を書くといったい何が良いのか、説明したいと思います。
try~catch文について
まずは、本題に入る前にtry~catch文について説明したいと思います。
try~catch文とは、例外を検知するために使われるものであり、例えば以下のようにコードが書かれます。
@SuppressWarnings("finally")
private static int divideZero() {
int operand1 = 10;
int operand2 = 0;
int retResult = 0;
try {
//0で除算してわざと例外を発生させてみる
retResult = operand1 /operand2 ;
}
catch (Exception e) {
//例外処理
e.printStackTrace();
}
finally {
return retResult;
}
}このソースの中に今回説明したい表記が含まれていますが、いったん我慢してtry、catch、finallyについて説明します。
tryの中にはエラーを検知したい処理を記述します。
tryの中にある処理に何も問題がなければcatchの中に書いてある処理は実行されません。
catchの中にはtryの中で書いた処理で例外が発生した場合に実行する処理が書かれます。
稀にcatchの中に何も処理がないコードを見るのですが、絶対にそのようなコードを書いてはいけません。
エラーを無視して次の処理に進んでしまうため、後続の処理で致命的なエラーが発生してしまう可能性があるからです。
そして、finallyですが、例外の発生の有無関係なしに最後に実行する処理を記述します。
例外が発生した時、そうではない時、いずれの場合も何かしらの処理を行ってメソッドを終了したいことが、開発の現場では時々あります。
その際にfinallyを記述して処理を書いておくことで、例外が発生した時、そうではない時に共通して最後に行う処理を書くことが出来ます。
このソースではreturnを使って値を返していますが、ログを出す処理をfinallyに入れて、後続の処理を行うケースもあります。
e.printStackTrace()とは何なのか?
では、本題に入りたいと思います。
先ほどお見せしたコードの実行の前に、このコードのe.printStackTrace()を除去して以下のようなコードにしてから、処理を実行してみます。
public static void main(String[] args) {
System.out.printf("計算結果は%dです。", divideZero());
}
@SuppressWarnings("finally")
private static int divideZero() {
int operand1 = 10;
int operand2 = 0;
int retResult = 0;
try {
//0で除算してわざと例外を発生させてみる
retResult = operand1 /operand2 ;
}
catch (Exception e) {
//例外処理
}
finally {
return retResult;
すると、以下のようにエラーを無視して処理が終了してしまいました。
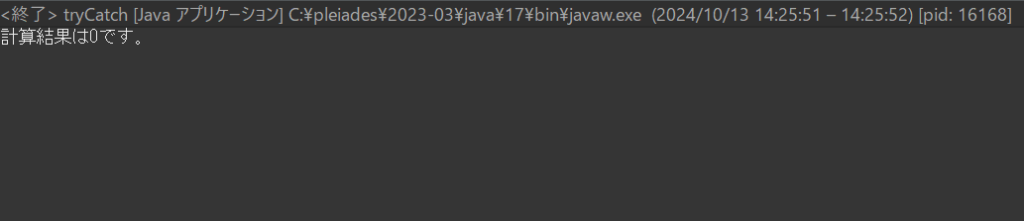
結果がこの表示になっている理由は、divideZero()のメソッドの中で、メソッドが返す値retResultを0に初期化していますが、tryの中に記述した除算処理で例外が発生したため、値が更新されていないためです。
ここまで露骨な0除算エラーを書く人はいないと思いますが、除算に使う変数の中に何の値が入っているかが分からない時に0が入っていることに気づかずにコードを書いてエラーを起こしてしまうことがあります。
そのため、上記のようにcatch文に何も書かれていないソースはtry~catch文を使った意味がなく、コードとして不適切であるといえます。
次に、catchの中にe.printStackTrace()を記述して何が起こるのか見てみます。
ソース
public static void main(String[] args) {
// TODO 自動生成されたメソッド・スタブ
System.out.printf("計算結果は%dです。", divideZero());
}
@SuppressWarnings("finally")
private static int divideZero() {
int operand1 = 10;
int operand2 = 0;
int retResult = 0;
try {
//0で除算してわざと例外を発生させてみる
retResult = operand1 /operand2 ;
}
catch (Exception e) {
//例外処理
e.printStackTrace();
}
finally {
return retResult;
}
}動作結果
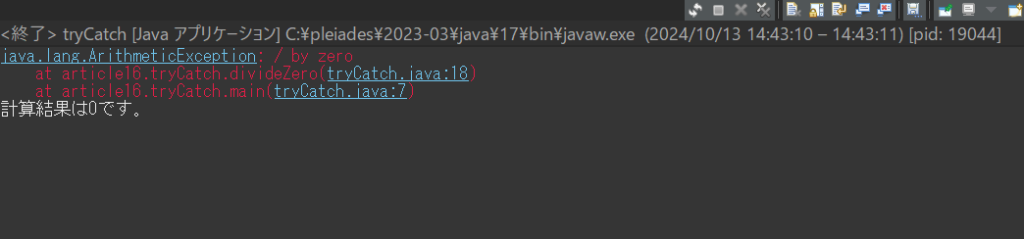
何かコンソールに表示されました。
この表示にはどんな例外が起きたかの種類、そしてどこで例外が起きたかの場所が記されており、実行からエラーまでに参照したメソッドの一覧(コールスタック)が表示されています。
コールスタックは先入れ後出しなので、エラーが出力される情報は一番上が最後に実行した内容、一番下が最初に実行した内容になります。
今回はシンプルなプログラムなのでこのレベルの表示になっていますが、いくつものメソッドを経由して実行した時、どの処理で落ちたのかが分からなくなる時があります。
そのため、このようにe.printStackTrace()を入れておくことで、どこで例外が発生したか、どこを修正すれば問題が解決するかの手がかりになるのです。
基本的にJavaはきちんとエラーの場所を教えてくれるので、e.printStackTrace()などを入れてコンソールに表示をさせると、コンソールの内容から問題個所を特定して修正が可能になっています。
なので、実際にJavaを使ってプログラムを組む場合は、エラーが起きた際にどんな処理を通ったのかを表示してくれる仕組みをe.printStackTrace()などを使って、表示させるようにした方が良いです。
これがあるのとないのとでは開発の効率が大きく変わってきます。
まとめ
今回のまとめです。
今回お話ししたかったことは、
try~catch文のcatchの中にe.printStackTrace()を書いておくと、Javaがコンソールにエラーの場所が特定できる情報を表示してくれる
ということです。
ちなみに、e.printStackTrace()のeは
catch (Exception e) {のところでeという変数を定義しているからであり、変数を別名にしたらe.printStackTrace()のeも別の名前になります。
なので、e.printStackTrace()とeまで含めて覚えるのではなく、
<変数名>.printStackTrace()
と覚えたほうが良いでしょう。
例外が起きた時に、その場所を特定しないといけないことはプログラム開発の現場で良くあることです。
なるべく早く例外が起きた場所と例外の種類を知ることで、どこのコードを修正すればいいかが分かりますので、例外発生時にエラーが起きた場所が特定できる仕組みは必ずプログラム中に入れた方が良いでしょう。
その一つが今回紹介したe.printStackTrace()となります。
今回の記事はここまでとなります。
また次の記事でお会いしましょう。










